当前,技能在每家公司的人才计划中都是不可或缺的,因此,我们的常驻人工智能专家 Rabih Zbib 将倾囊相授,阐释机器学习和人工智能借助技能语义学的形式为公司分忧解难。
Rabih 目前在 Avature 担任自然语言处理与机器学习总监。他拥有麻省理工学院的博士和科学硕士学位,并致力于通过人工智能视角改善人才战略。
人才管理的世界正在经历着结构性的变化,其中,技能在人力资源团队获取和管理人才方面,发挥着核心作用。随着这一进程的加快,在进行候选人寻源时,对自动提取和评估技能的需求也跟着水涨船高。 对技能的渴求使得技能被称为“人才的新货币”。
我们已经在之前的文章中描述了 Avature 的技能管理方法和人工智能的作用,本文中,我们将重点讨论其中的一个关键方面:技能语义学。换句话说,就是理解技能含义的学科。
为什么技能语义学很重要?
如果技能被用作指标,来衡量实现某一结果所需的具体知识或专长,那么要评估候选人是否适合某一岗位,就需要了解候选人的技能和岗位所要求技能的含义。尽管这种讨论可能过于理论化,我们仍需要探讨在这一语境下,“含义”的定义是什么。
一般来说,一个词的含义可以被认为是该词在现实世界中所指的一组对象或概念。例如,椅子的含义是指世界上所有的椅子,包括实体的和概念上的。这个定义在语言学中被称为指称语义学。另一种观点是分布式语义学,认为一个词(或术语)可以通过其分布来定义,也就是说,通过它经常出现的语境来定义。这一假设被称为“分布式假设”。
“你应该通过上下文来理解一个词。”
语言学家 John Rupert Firth
对于技能语义学来说,这是一个很有帮助的定义,因为我们需要做的是比较技能,并确定一种技能与另一种技能的相关性。但在这里,完全匹配技能名称显然是不够的,因为技能可以用其他名称来指代(例如编程与软件开发)。此外,如果一个人拥有某种技能,那么可能表明他们可能还拥有另一种技能。举个例子,假设您对拥有编程技能的候选人感兴趣。在这种情况下,即使一个人的简历中没有明确写出“编程”这一技能,但他们拥有 Java、C++ 或 Python 经验,那么此人显然是一位熟练的程序员。
人工智能的作用
由此可知,我们有必要明确技能之间的关联,以便有效地利用它们进行人才管理。换句话说,我们需要利用技能语义学。然而,我们不希望通过人工的知识工程来建立这些信息。因为人工建立有很多劣势。首先,它需要多个行业和部门的详细专业知识。此外,它很脆弱且不易延展。新技能不断涌现,技能的含义和彼此之间的关联也会随着时间的推移而变化,因此我们需要一种自动化的方法来学习技能语义学。
在这里,人工智能扮演了至关重要的角色。我们可以利用机器学习模型,从真实数据中自动学习技能的含义。这个过程可以用新技能和新数据来重复进行(可扩展),而也不需要多个领域的深厚专业知识。
技能嵌入
那么,如何利用分布式语义学,来学习技能的含义呢?我们采用了一项在自然语言处理中十分流行的技术:词嵌入。这种技术也被称为 word2vec,是将每个词表示为高维空间(如100)中的一个点(或向量嵌入)。
将每个词映射到嵌入空间中相应点的算法,依赖于我们上面提到的分布式假设(即出现在同一语境中的词具有关联含义)。更具体地说,一个神经网络被训练为根据该点的上下文词,来预测每个词的嵌入位置。
我们调整词嵌入来代表技能,每个技能对应嵌入空间中的一个点,即使技能包含一个以上的词也是如此(例如:特定电器的集成电路)。在这个意义上,嵌入空间中的每个点都代表一个概念而不是一个词。我们评估 skill2vec 嵌入的方式与评估 word2vec 嵌入的方式类似,即通过对技能数据对深度神经网络模型进行训练。
我们首先从匿名的简历和岗位描述中收集相关技能集。例如,我们可以提取以下岗位:
- 岗位名称:模拟设计工程师
- 技能:设计,测试,电路设计,Verilog,锁相环……
我们通过隐藏一项技能(例如电路设计)来训练深度神经网络,并强迫模型从其他“上下文”技能中对其进行预测,包括:设计、测试、Verilog、锁相环……
最初,深度神经网络会在预测中出现错误,但通过使用标准的反向传播算法,训练过程会让深度神经网络的参数得到更新,以减少这些错误。这个过程要经过多次迭代,使用数以百万计的数据样本(我们的常规设置使用约4500万条岗位记录),直到深度神经网络参数汇集了一组足以减少预测误差的值。
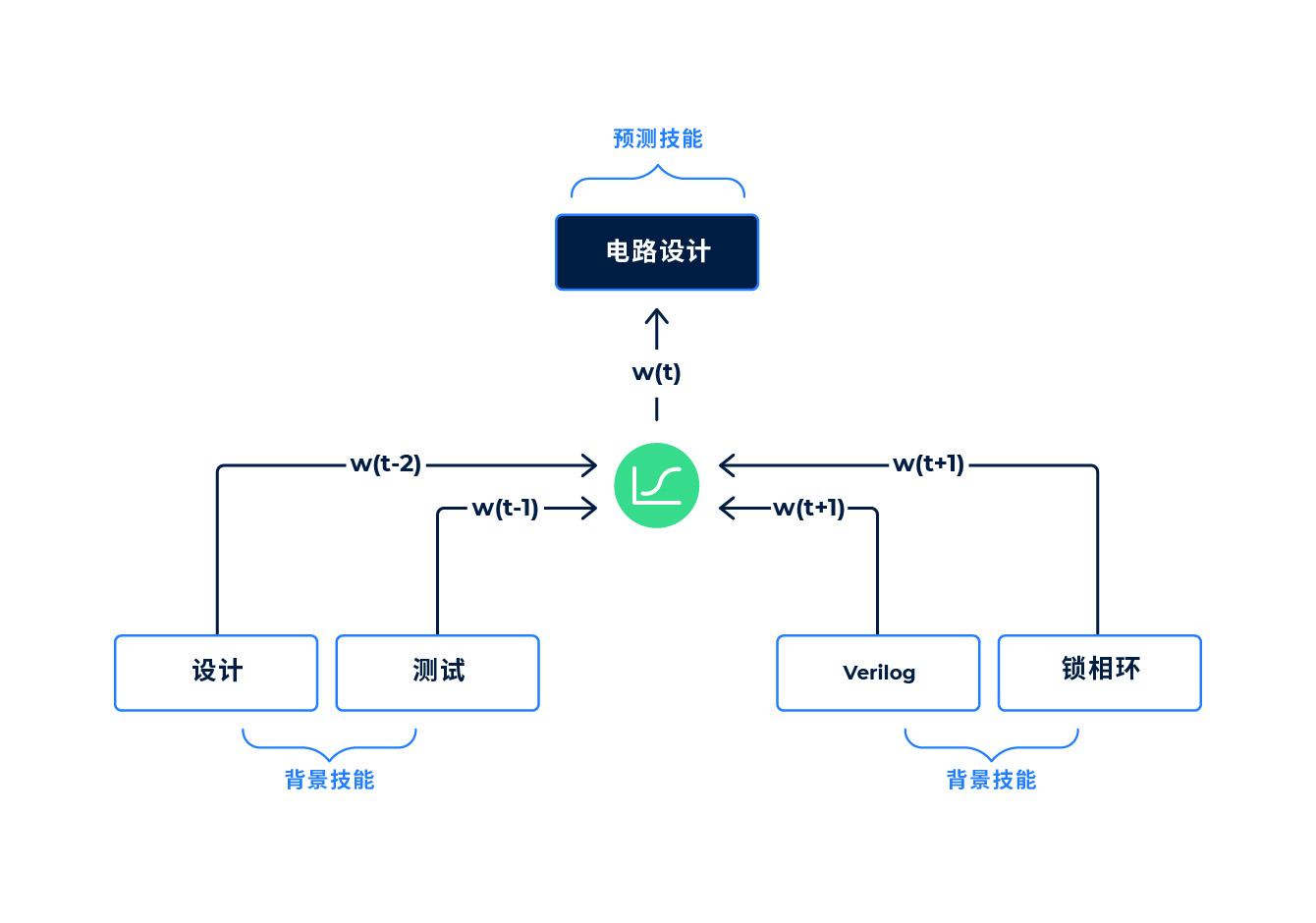
技能嵌入培训示例。
由此产生的深度神经网络现在可以将每个技能映射到嵌入空间的一个点上。但这种映射具有一个重要特性:在相似背景下出现的技能(即具有相似含义) 会在嵌入空间中彼此靠近。这一点至关重要,因为这让我们能够通过测量 skill2vec 空间中的嵌入距离,来定量地衡量技能含义的相似程度。例如,在我们的嵌入中,我们得到了SIMILARITY(软件开发,JAVA):0.7136,而SIMILARITY(软件开发,木工):0.0706,前者的数值比后者高了10倍。
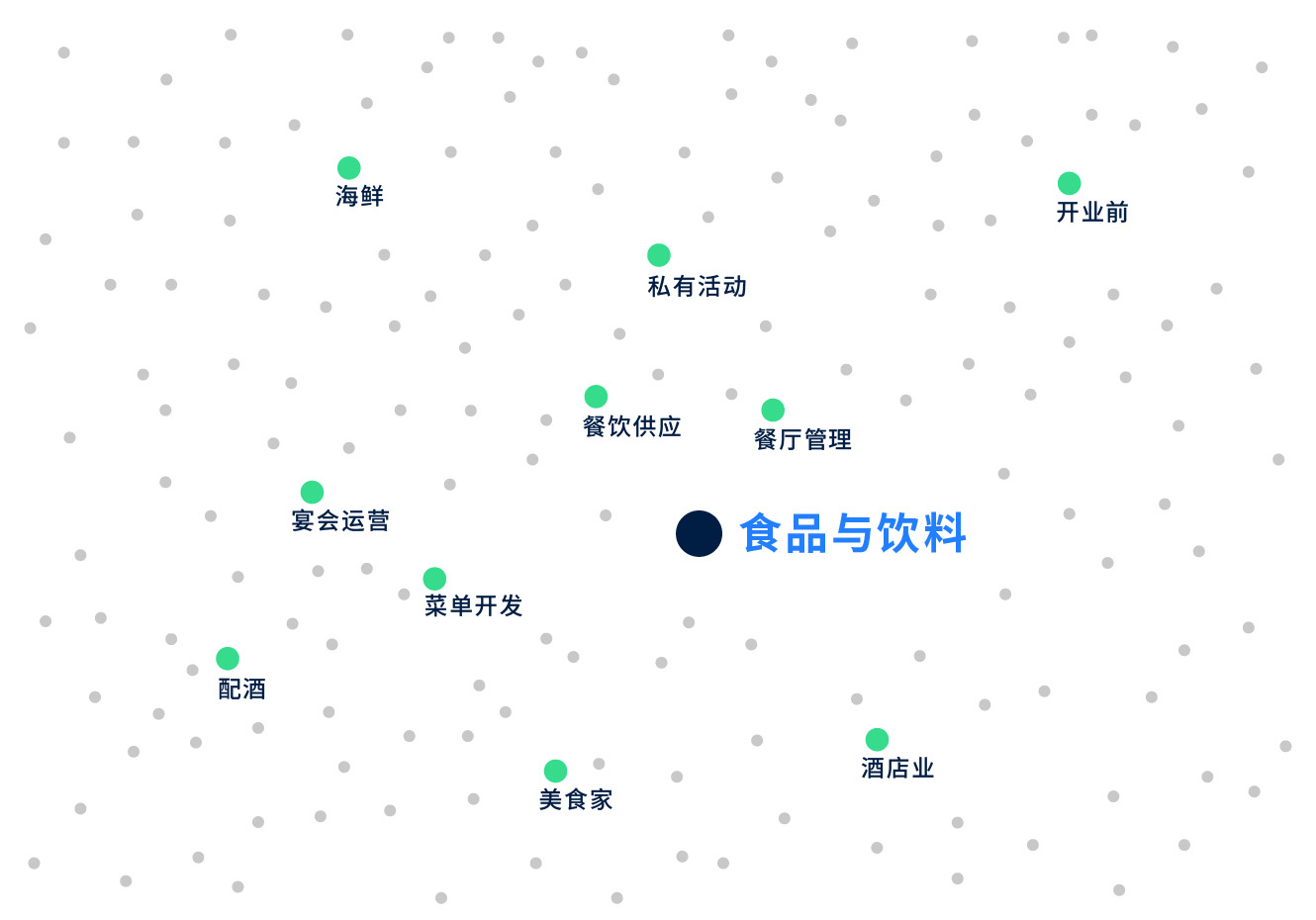
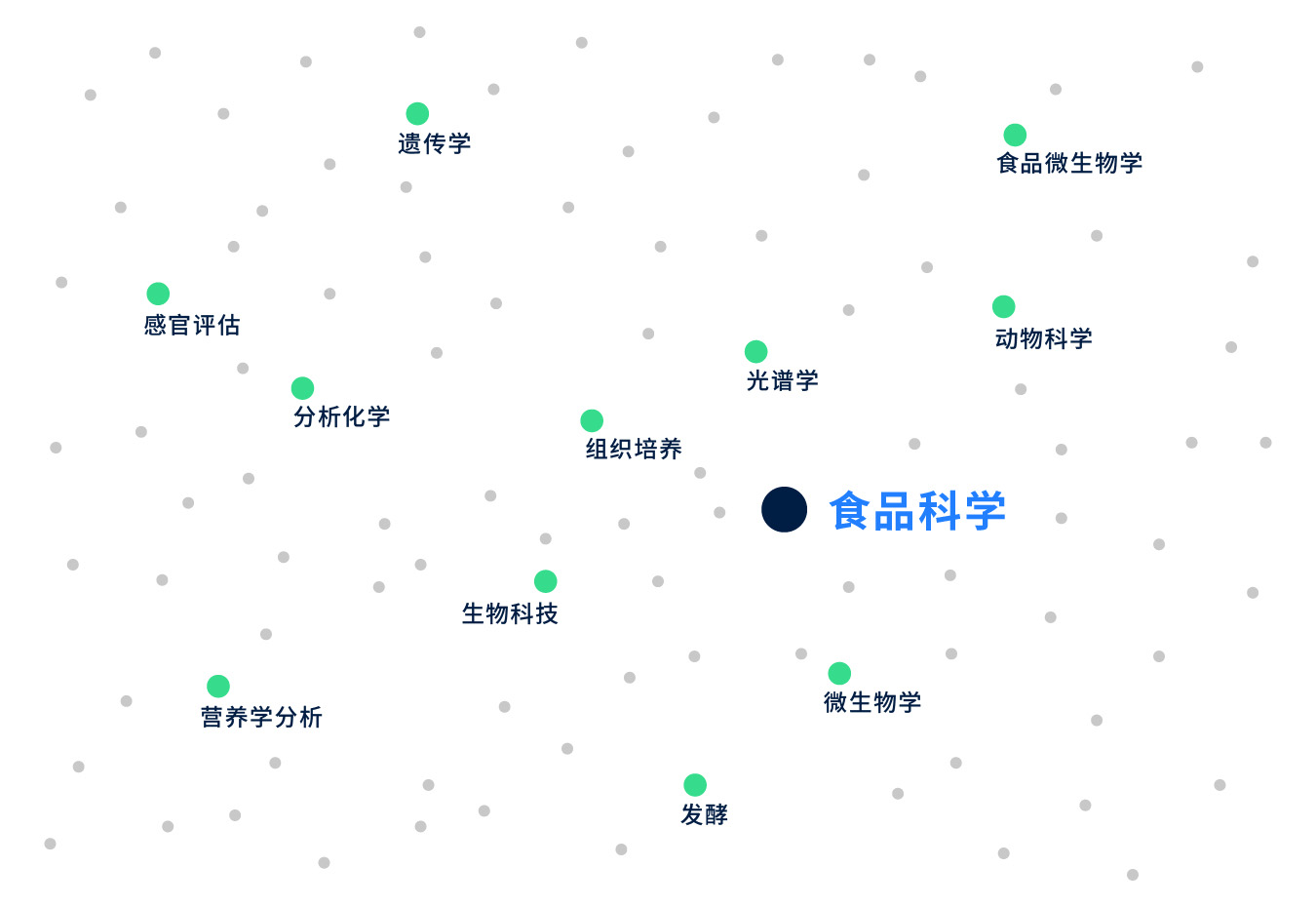
让我们看一个例子,来进一步说明技能嵌入的特性。思考一下这两种技能:食品与餐饮服务,以及食品科学。 如果我们来看与食品与餐饮服务关系最密切的技能,我们会找到餐厅管理、烹饪、餐饮服务、菜单开发等。但是当我们看到与食品科学最接近的技能时,我们会找到分子生物学、分析化学、聚合酶链反应和感官评价。
我们看到,这两种技能有非常不同的近邻,因为它们与两个不同的行业有关(食品服务业与食品开发及制造业),并且各自意味着一套不同的技能.尽管两种技能中都包含了食品一词,技能嵌入通过捕捉技能语义,超越了关键词的限制。
与“食品和饮料”技能最接近的邻居
与“食品科学”技能最接近的邻居
总结……
技能嵌入是许多人工智能功能的基石。它们被用来进行基于技能的匹配或相关技能的提示。 在下一篇文章中,我们将阐述如何使用技能嵌入来训练一个模型,以衡量职衔之间的相似性。
如果您喜欢这个关于人工智能和机器学习如何共同运作的内部观察,并想了解更多,请与我们联系。您还可以观看我们对Fosway的采访,在这一视频中,我们更深入地讲解了 Avature 的人工智能白盒方法。
