对于希望提供高接触度候选人体验的公司而言,智能岗位推荐已成为企业招聘官网的一项关键功能,实现访客与相关工作机会的匹配。这一技术也让招聘人员如虎添翼,可以更加高效地识别出合格的候选人。
从技能到教育背景,在建立候选人与开放岗位的匹配度时,具有匹配功能的系统可以将多种变量纳入考量。其中,过往经验(尤其是职衔相似度)是主要因素之一。
我们的机器学习研究团队基于技能语义能力开发了一种创新方法,依靠无监督学习模式获取职衔之间的语义相似度。
我们与 Avature 常驻人工智能专家兼自然语言处理和机器学习总监 Rabih Zbib 讨论了这项工作中最值得注意的几个要点。它们均已发表在研究论文《从噪声技能标签中学习职衔相似度》中,包括模型的训练方式和工作原理,以及该模式如何让 Avature 和我们的客户从中受益。请继续阅读,从而了解这一强大的人工智能引擎如何支持我们的平台。
这种方法有哪些让人耳目一新的地方?
我们希望该模型能够对比两个职衔并推断它们之间的相似程度。实现这一目标的传统解决方案是开发一个监督模型。该模型在一个庞大的职衔配对数据集里进行训练,它由人工手动注释,来定义职衔之间是否彼此相似。但注释如此庞大的数据集是一个缓慢而严格的过程,因此我们的机器学习研究人员采用了不同的方法,使用职衔的语义表征来训练模型。
我们稍后将讨论该模型的技术细节。在此之前,要重点介绍和当前市场中其他路径相比,该模型的两个与众不同之处:
- 该模型依赖于无监督学习。这是人工智能领域中一项革命性的方法,更具通用性,成本效益也更高。因为它不需要人工注释,所以可以使用更多数据进行扩展。
- 因此,该模型可以实现更快的开发和部署,从而为我们的客户带来显著的短期及长期价值。
为什么要朝这个方向发展?
Avature 创新的动力在于通过提供强大的工具来增强客户的人才流程,为客户创造价值。此刻亦是如此。我们选择采用这种方法是因为它为我们的客户带来了诸多好处:
- 我们通过人工智能支持的用例为客户的招聘人员节省了大量时间,从整体上提升每一位卷入人才相关流程的利益相关者的体验。当我们引入新模型来加强我们的跨平台人工智能并进行快速部署时,我们也确保了客户能持续从中受益。
- 由于该模型在语义层面上运行,因此该模型允许对职衔进行智能比较,而不仅仅是字面上的关键字匹配。此外,该模型可以泛化,这意味着即使是训练数据中未包含的职衔该模型也可以预测其相似度。这是一个巨大的好处,因为在职场上,新的职衔会不断涌现。
- 无需人工注释即可构建机器学习模型,使我们能够更快地更新模型,防止模型过时。随着劳动力市场的变化,我们会定期更新人工智能核心技术的能力,确保我们的客户能始终获得准确的结果,避免模型漂移的负面影响。
- 用于训练职衔模型的语义表征独立于语言。通过这种方法,除了英语之外,我们还开发了法语、德语、西班牙语和意大利语功能。同时我们的产品蓝图里还包括了其它语言。对于许多跨国运营的全球性客户来说,能够持续利用我们的多语言人工智能功能意义非凡。
该模型如何运作
在之前关于技能语义的博客中,我们描述了如何将技能在高维语义空间中建模为向量或点。该空间采用神经网络模型,使用真实数据进行训练。因而能够根据空间中对应点之间的距离衡量技能之间的相似程度。技能的语义通过这些向量(称为嵌入)来进行表征,这就是所谓的表征学习。
现在,让我们回到职衔。Avature 机器学习团队认为我们可以从相关技能的表征中获得职衔的表征。为此,他们从数百万份岗位需求和匿名简历的工作经验中提取技能,然后将其与相关职衔进行关联。
在一个庞大的数据集上,从不同数据记录中提取对应同一职衔的技能并将其组合在一起。这能够帮助跟踪某项技能与同一职衔同时出现的频率。最终的结果呈现如下:
传播总监:{“公共关系”:135,“社交媒体”:128,“营销活动”:93,“写作”:55,“战略”:18,……}
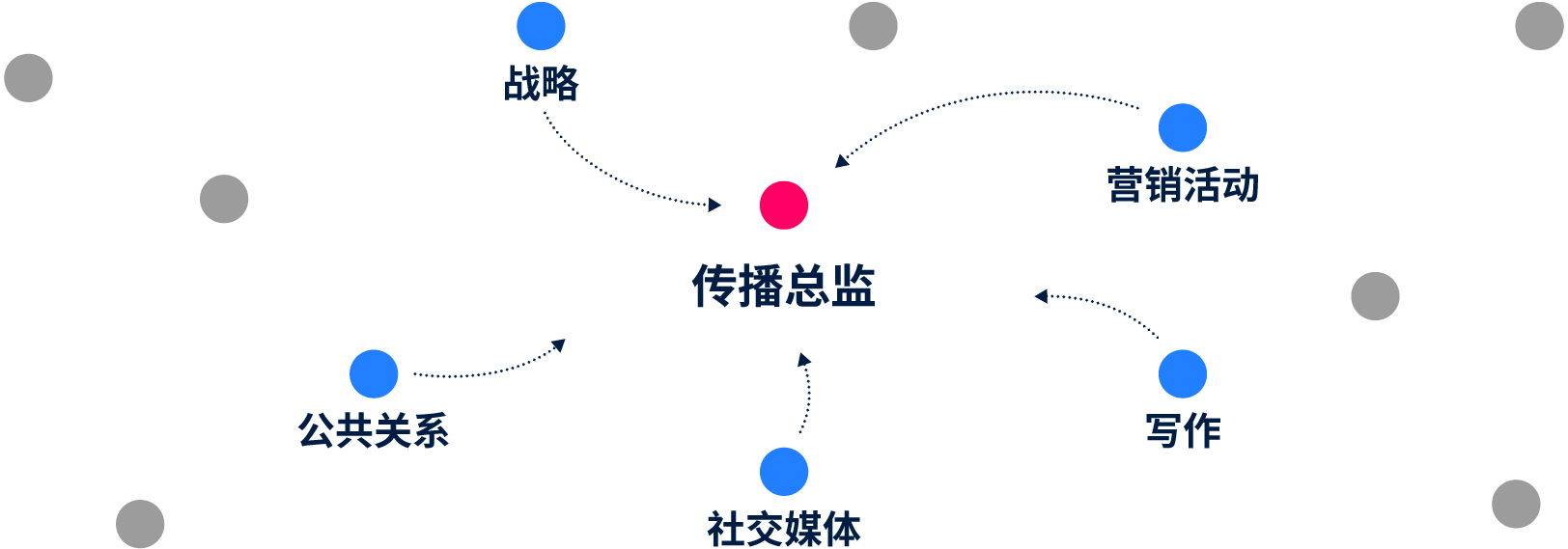
图1从相关技能中获取职衔的表征。
然后,计算所有相关技能嵌入向量的平均值,然后使用该计数作为权重来反映每种技能的重要性,从而获得职衔的语义表征。这种表征可以直接用来对比职衔的相似度。
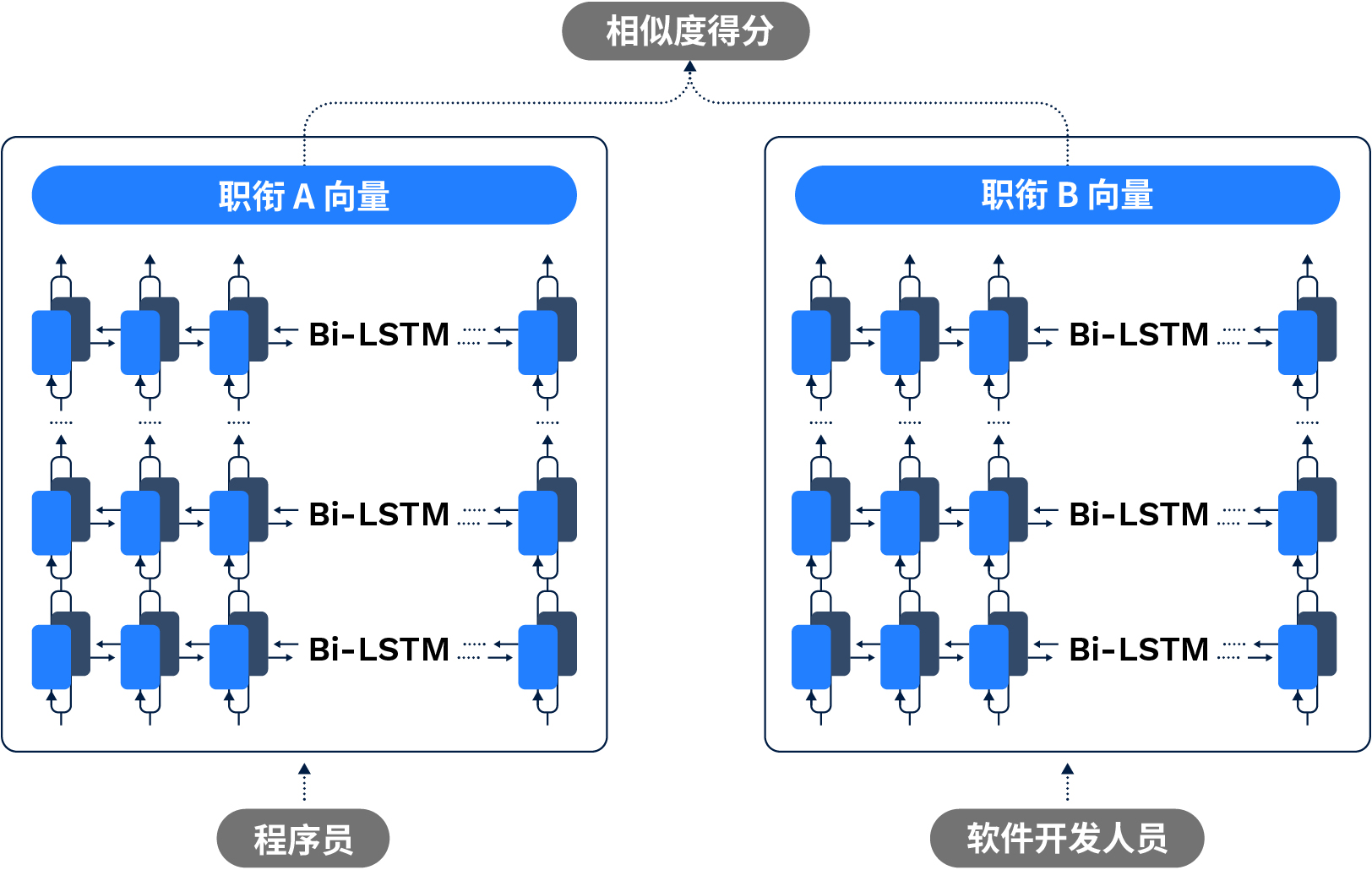
图2实际使用的职衔模型示例。循环神经网络为每个职衔生成一个嵌入向量,捕获其语义。然后比较两个向量,以确定它们相应嵌入之间的相似度。
但这仅限于在训练数据中出现次数足够多的职衔。为了确保该模型的泛化能力,我们想走得更远。因此,我们的研究人员使用这些作为职衔(或人工智能术语中的“目标”)的理想表征,并训练循环神经网络(简称 RNN)来模仿该理想表征。
经过训练后,RNN 就可以根据职衔生成这样的表征。这包括训练数据中未出现过的新职衔。
该模型的另一个重要特征是它不需要相关技能来生成职衔的嵌入。相关技能仅用于训练模型。因此,团队实现了我们为自己设定的目标:该模型可以根据语义比较两个职衔,并且使用无监督表征而不是缓慢且昂贵的手动注释进行训练。
使用技能语义作为职衔的表征也使我们能够克服人工智能开发中最顽固的瓶颈——数据。尽管技能是用特定语言(例如英语)表达,但作为概念,它们独立于语言。“公共关系”仍然与“社交媒体”相关,无论这些技能是用英语还是德语表达。这意味着,如要获得新语言的训练数据,我们只需翻译该数据的职衔并按原样重新使用语义表征即可。得益于这一特性,我们可以用新语言进行训练,并在极短时间内部署适用该语言版本的人工智能模型。
透明度和灵活性的开发
ChatGPT 等工具以前所未有的方式将人工智能推向主流。但在招聘中,围绕这项技术的讨论和担忧并不鲜见。事实上,这些担忧正在推动强化这一领域的监管。例如,美国纽约市通过了一项法律,要求雇主对自动就业决策工具(包括利用人工智能的工具)进行偏见审计。
我们深知公正和公平的人才流程对我们的客户来说至关重要,因此我们不会使用种族、年龄、出生地和性别等个人信息来训练我们的原生人工智能模型。不仅如此,在训练人工智能模型时,我们还避开了人类决策的历史数据来从而避免隐性偏见。我们基于表征的方法另辟蹊径,通过候选人个人资料的属性语义进行建模,例如技能或职衔。我们训练职衔模型的方法遵循公正透明的理念。
但透明度的前提超越了模型训练的范畴。对每种不同类型的属性使用基于表征的模型,使我们能够实现人工智能的白盒方法,帮助 Avature 用户完全了解和控制系统的内部运作,使其决策得到增强,但又不会被完全取代。
我们先是开发了技能语义,现在又开发了职衔相似度。通过努力开发机器学习模型,我们为有影响力的解决方案提供支持,以简化客户的招聘和人才管理计划。最重要的是,我们的目标是开发能够应对未来挑战的灵活技术。
几年前,我们决定构建原生人工智能算法。这使我们能够与客户密切合作,根据他们的愿景和需求进行创新。我们的客户能够充分接触模型背后的专家。这一点与那些将人工智能开发外包的供应商形成鲜明的对比。如果您也想与我们的专家交流并了解有关我们机器学习模型和整体人工智能功能的更多信息,请与我们联系。
如果您想阅读论文全文,请访问以下链接:
Rabih Zbib、Lucas Lacasa Alvarez、Federico Retyk、Rus Poves、Juan Aizpuru、Hermenegildo Fabregat、Vaidotas Simkus 和 Emilia Garcıa-Casademont,2022年,《从嘈杂的技能标签中学习职衔相似度》,arXiv:2207.00494 [cs.IR]


